|
I am a senior researcher at Dolby Laboratories. I earned my PhD in Computer Science from the University of Maryland, College Park, my dissertation, "Learning from Less Data: Perception and Synthesis," explores data-efficient AI. Prior to this, I was an undergraduate at the Indian Institute of Technology Madras, where I obtained a bachelors degree in Electrical Engineering, and masters degree in Data Sciences. My research interests encompass the intersection of generative AI, computer vision, and multi-modal learning. My goal is to advance computer vision, generative, and multimodal AI systems by developing methods grounded in core principles that are both foundational and application‑driven. I seek to contribute to solving diverse and challenging problems, enabling real‑world impact. Email / CV / Google Scholar / Twitter / Github |

|
|
|
|

|
Divya Kothandaraman, Ming Lin, Dinesh Manocha ACMMM 2025 (Oral) arXiv / GitHub An approach for concept blending using novel perspectives from the Black Scholes model in economics and finance. |

|
Divya Kothandaraman, Tianyi Zhou, Ming Lin, Dinesh Manocha MIPR 2025 (Oral) arXiv / GitHub Mutual information and inverse perspective mapping guidance for text-controlled aerial view synthesis from a single input image using diffusion models. |

|
Divya Kothandaraman, Kuldeep Kulkarni, Sumit Shekhar, Balaji Vasan Srinivasan, Dinesh Manocha COLING 2025 arXiv / GitHub An approach for subject and action personalization using prompting techniques and concepts from image and signal processing. |

|
Divya Kothandaraman, Kihyuk Sohn, Ruben Villegas, Paul Voigtlaender, Dinesh Manocha, Mohammad Babaeizadeh AI4CC Workshop at CVPR 2024 arXiv Sequential and controlled autoregressive generation of the desired custom concepts for multi-concept customized video generation with transfoermer models. |

|
Divya Kothandaraman, Tianyi Zhou, Ming Lin, Dinesh Manocha Siggraph Asia 2023 (Conference Proceedings, Technical Communications) arXiv / GitHub A text-guided image to image diffusion model to generate aerial views from a single ground-view image. |
|
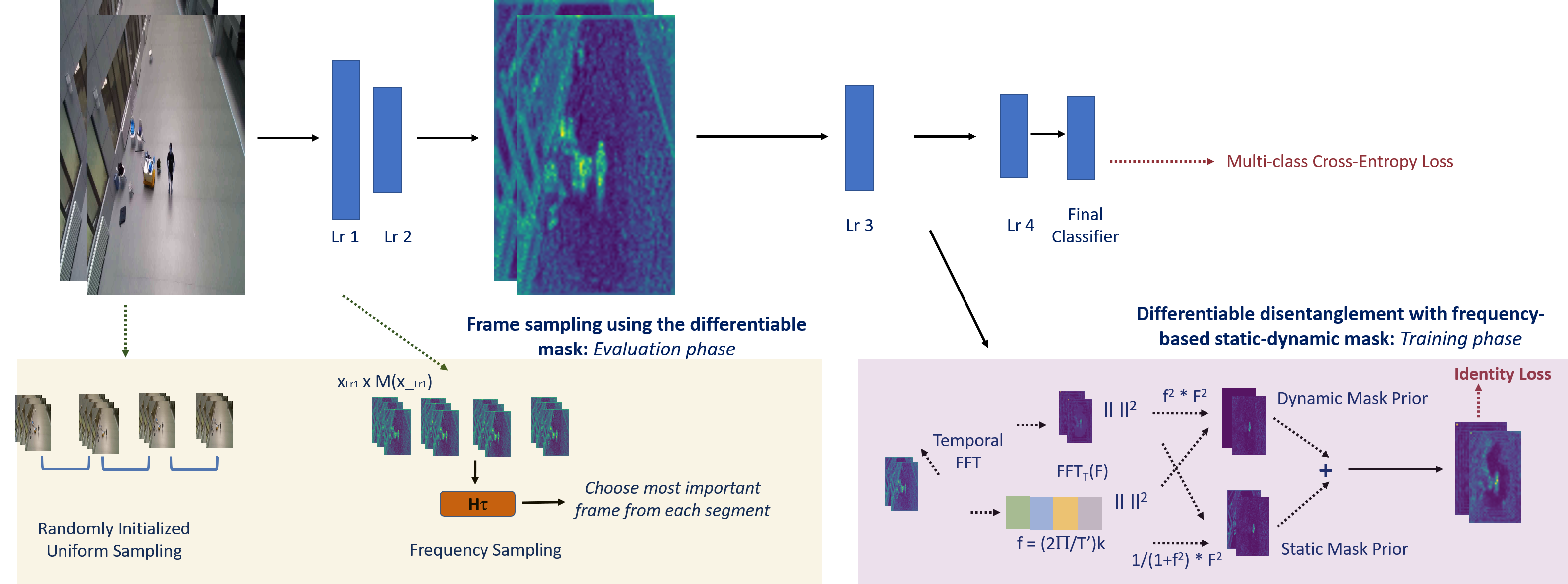
Divya Kothandaraman, Ming Lin, Dinesh Manocha ICRA 2023 arXiv / GitHub A differentiable feature disentanglement method to learn "static salient" and "dynamic salient" regions for aerial video action recognition. |
|
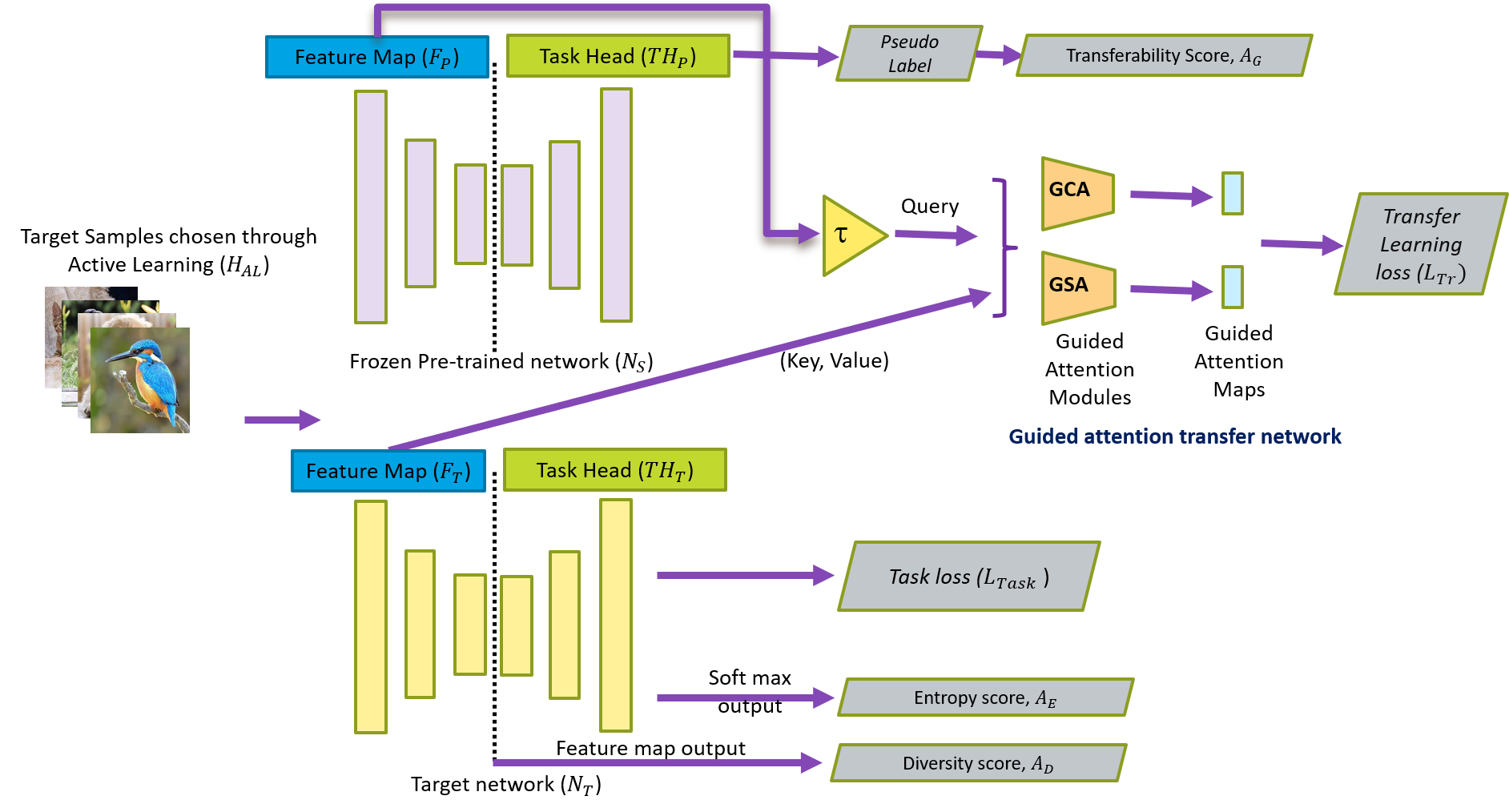
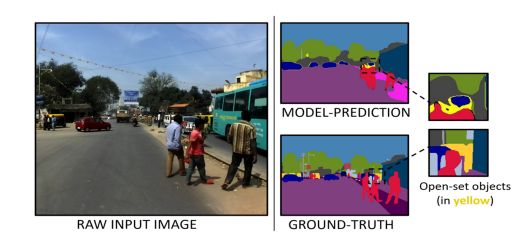
Divya Kothandaraman, Sumit Shekhar, Abhilasha Sancheti, Manoj Ghuhan, Tripti Shukla, Dinesh Manocha WACV 2023 arXiv / GitHub A generic source-free active domain adaptation method that can handle shifts in output label space. |
|
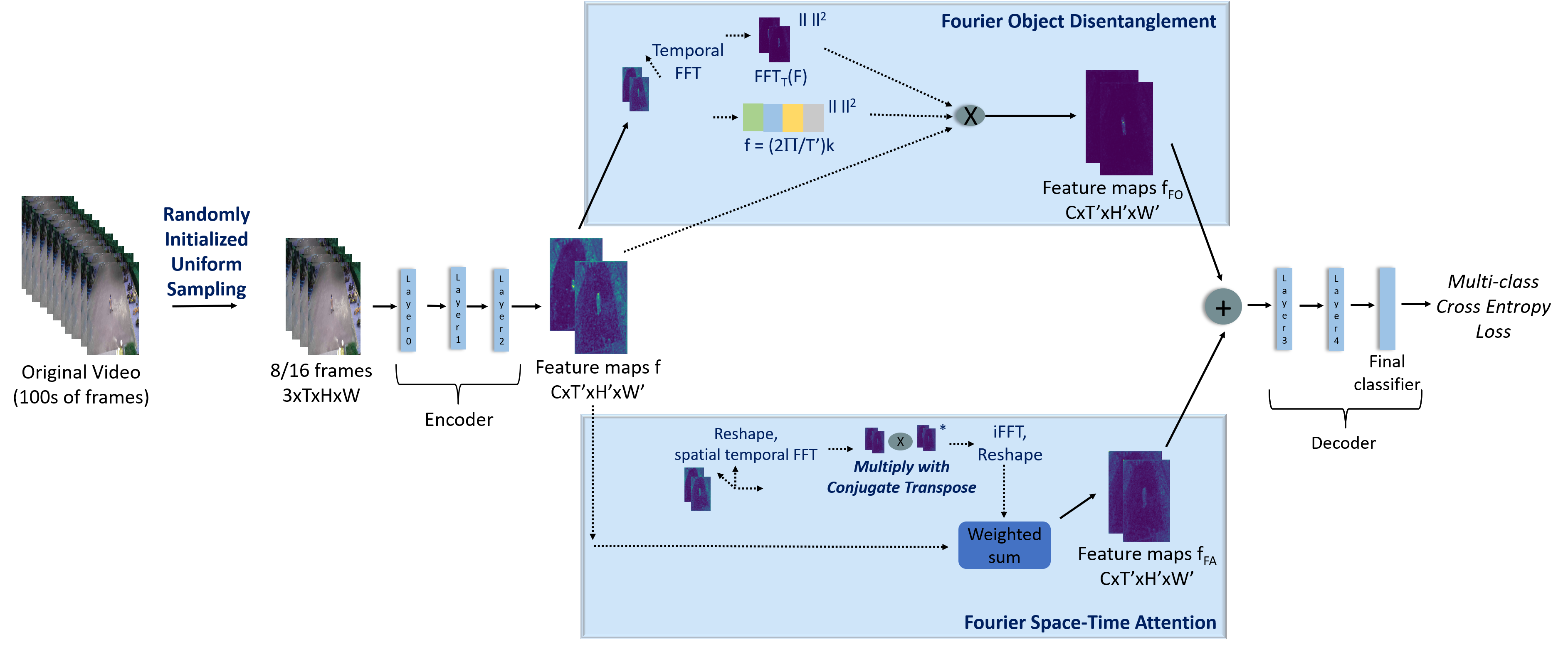
Divya Kothandaraman, Tianrui Guan, Xijun Wang, Sean Hu, Ming Lin, Dinesh Manocha ECCV 2022 Project Page / arXiv / GitHub An efficient aerial video action recognition method, with novel frequency domain techniques, vis-a-vis, Fourier object disentanglement and Fourier attention. |
|
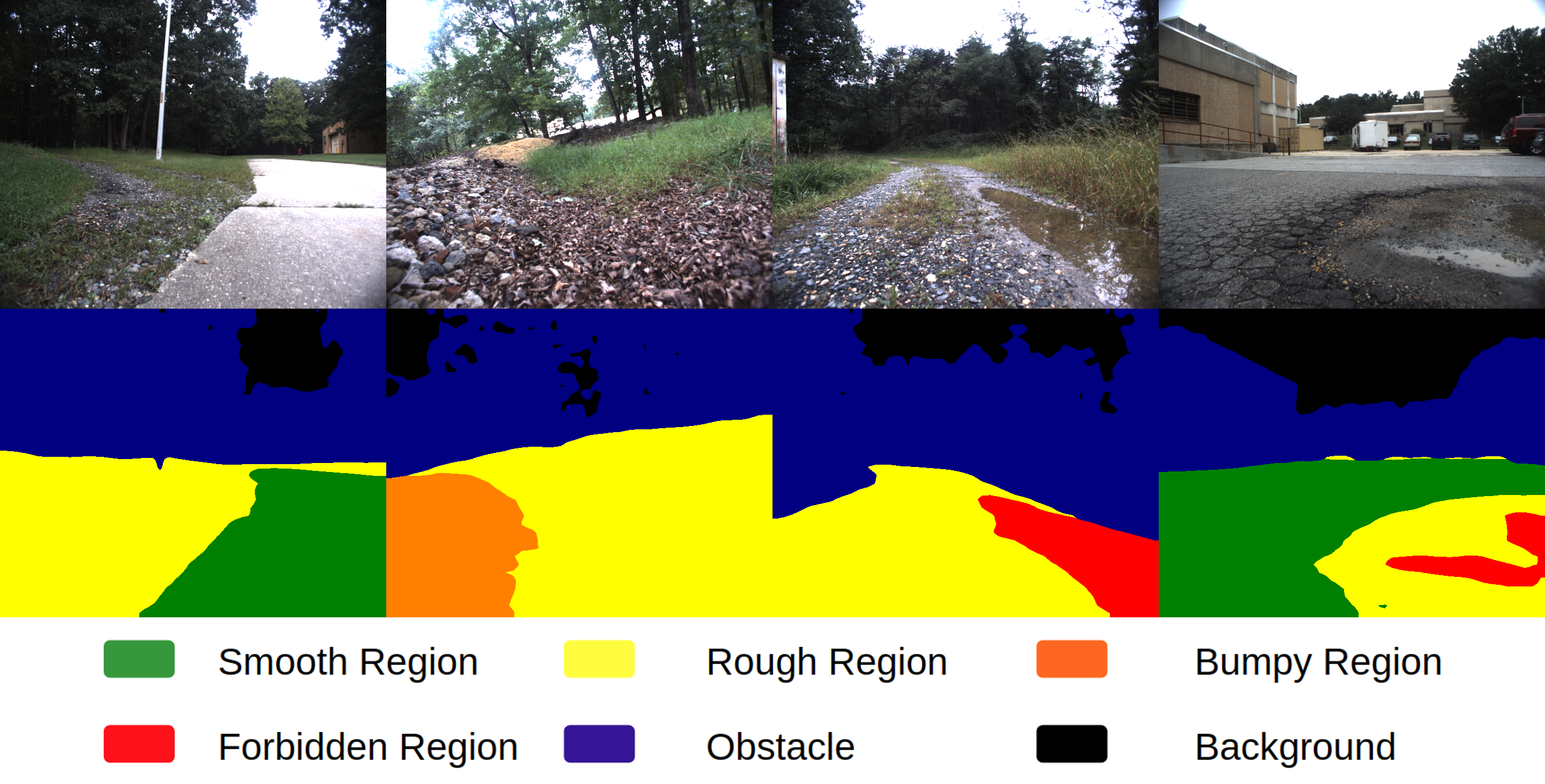
Tianrui Guan Divya Kothandaraman, Rohan Chandra Dinesh Manocha IROS 2022 and RSS 2022 Project Page / arXiv / bibtex An attention-based segmentation method for identifying safe and navigable regions in off-road terrains. |
|
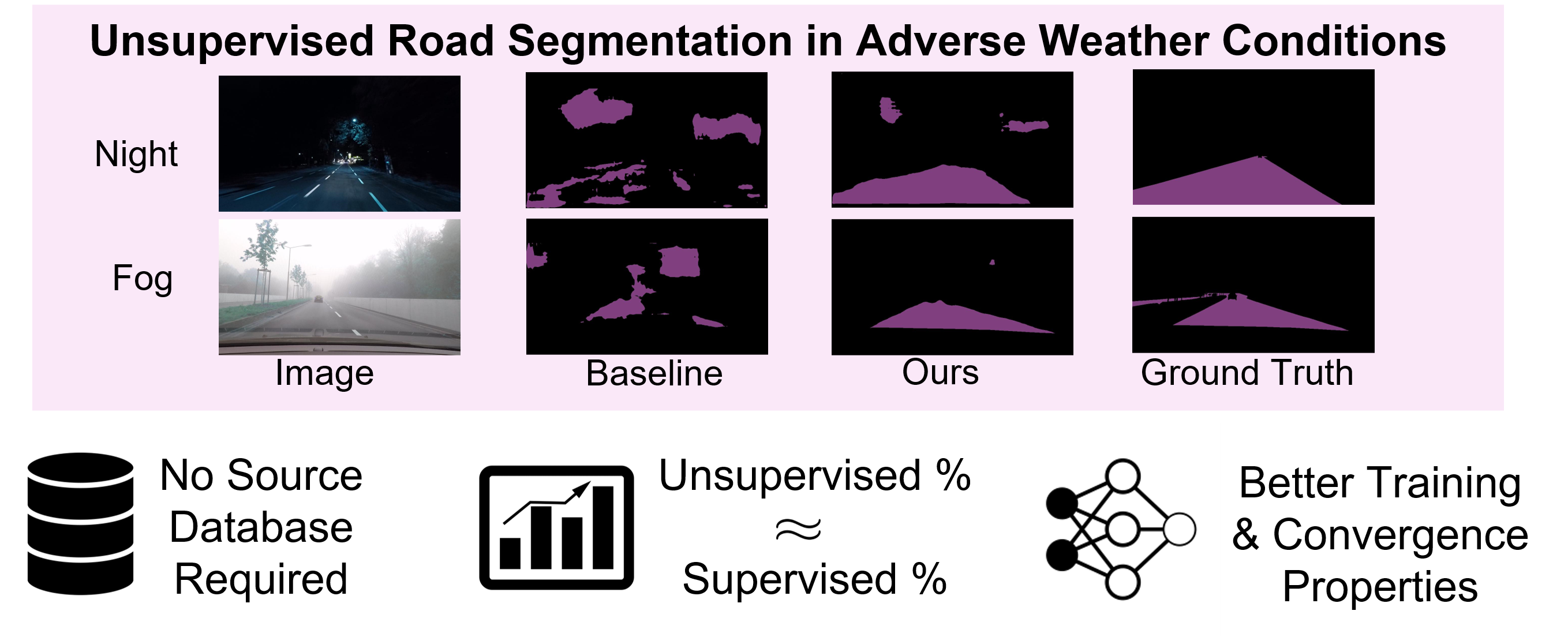
Divya Kothandaraman, Rohan Chandra Dinesh Manocha ICCV Workshops 2021 Project Page / arXiv / YouTube / GitHub / bibtex A self-supervised learning approach for source free unsupervised road segmentation in adverse weather environments and low light conditions. |
|
Divya Kothandaraman, Rohan Chandra Dinesh Manocha ICCV Workshops 2021 Project Page / arXiv / YouTube / GitHub / bibtex A multi-source boundless unsupervised domain adaptation algorithm for semantic segmentation in unstructured environments. |
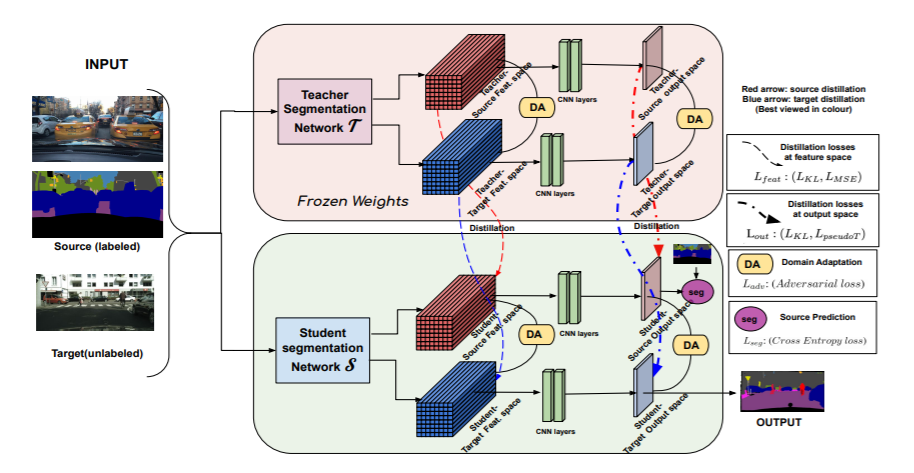
|
Divya Kothandaraman, Athira Nambiar Anurag Mittal WACV Workshops 2021 Paper / YouTube / GitHub / bibtex An approach for domain adaptive semantic segmentation in models with limited memory. |
|
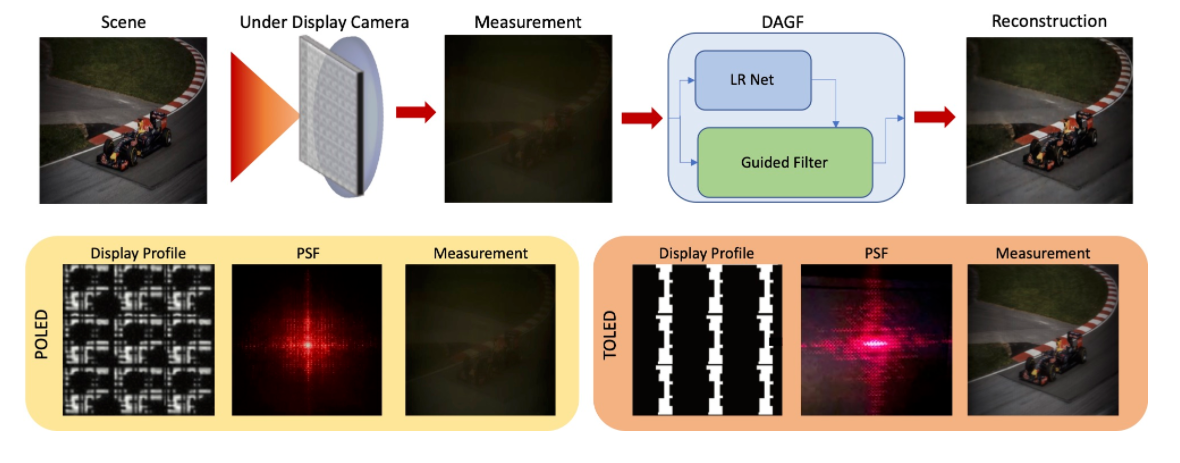
Varun Sundar , Sumanth Hegde*, Divya Kothandaraman , Kaushik Mitra ECCV Workshops, 2020 ArXiv / YouTube / Project Page / bibtex Guided Filters when incorporated in a deep network can efficiently recover severely degraded, mega-pixel resolution images. |